High-Performance Inter-Process Communication Between C and Python
October 11, 2024 | Inter-Process Communication
Exploring efficient inter-process communication between C and Python using shared memory and the LMAX Disruptor pattern. This article demonstrates how to share data between processes for high-performance applications, particularly in scenarios where a C process connects to data sources and needs to share this data with a Python process.
TL:DR
By using simple primitives, shared memory and atomic operations, we can easily achieve 2.6 Million messages per second passed between C and python processes.
Introduction
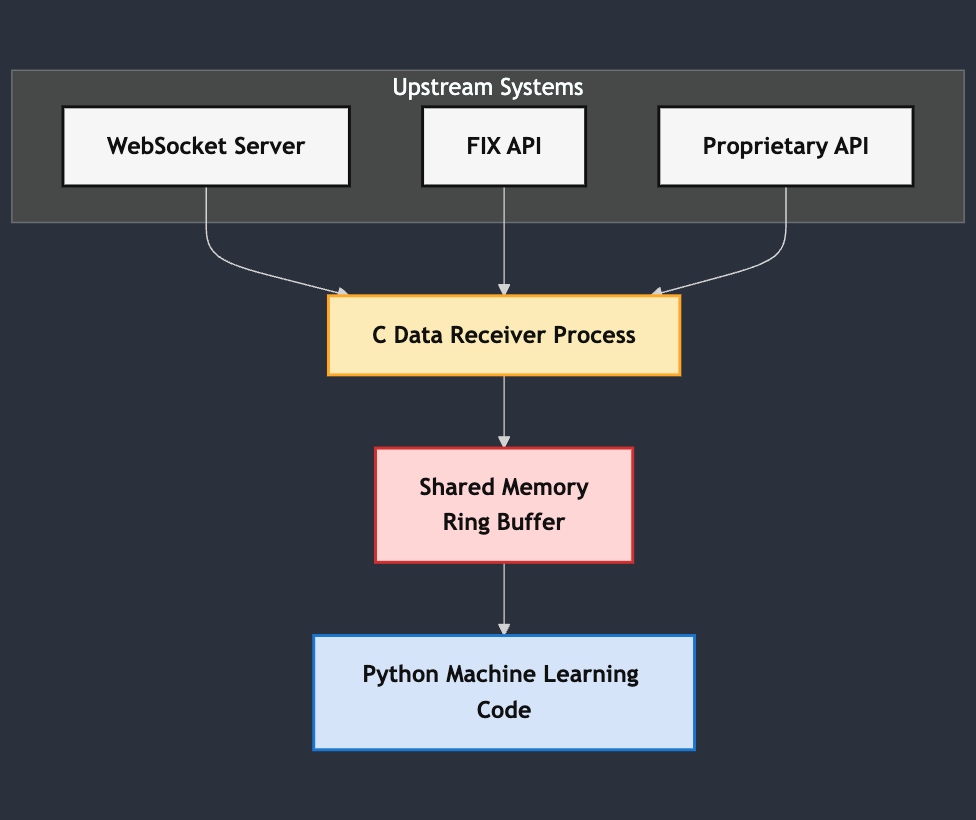
In high-frequency trading and other performance-critical applications, it's common to have a C process that connects to data sources like WebSocket, FIX, or proprietary APIs to receive real-time data. This data often needs to be shared with other processes, possibly written in different languages like Python, for further processing, analytics, or machine learning tasks.
Efficient inter-process communication (IPC) is crucial in such scenarios to minimize latency and maximize throughput. This article explores how to use shared memory and atomic operations to implement a high-performance ring buffer between a C producer and a Python consumer, inspired by the LMAX Disruptor pattern.
The LMAX Disruptor Pattern
The LMAX Disruptor is a high-performance inter-thread messaging library created by LMAX Exchange, a financial trading company. It was designed to achieve very low latency and high throughput in their trading platform. The key idea is to use a lock-free, single-writer, single-reader ring buffer that allows threads to communicate with minimal synchronization overhead.
While the original Disruptor is a Java-based library for inter-thread communication, the underlying principles can be adapted for inter-process communication. By leveraging shared memory and atomic operations, we can create a similar mechanism between processes written in different languages.
Implementing the Ring Buffer
We'll create a ring buffer in shared memory that allows a C producer process to write messages and a Python consumer process to read them. The ring buffer uses atomic indices for synchronization and a spinlock mechanism to manage access without the overhead of system calls or kernel-level synchronization primitives.
Shared Memory Setup
Shared memory provides a segment of memory that multiple processes can access simultaneously. In Unix-like systems, we can use POSIX shared memory APIs to create and manage these memory regions. Both the producer and consumer will map the shared memory object into their address spaces.
Ring Buffer Structure
The ring buffer consists of a fixed-size array of messages and atomic indices for reading and writing. Here's how it's defined in C:
// Define the RingBuffer structure
typedef struct {
atomic_ulong write_index; // Atomic write index
atomic_ulong read_index; // Atomic read index
char buffer[BUFFER_SIZE][64]; // Buffer to hold messages
} RingBuffer;
The `write_index` and `read_index` are used to keep track of where to write new messages and from where to read messages, respectively. By using atomic operations, we ensure that these indices are updated safely in a concurrent environment.
C Producer Code
The producer is responsible for connecting to data sources and writing messages into the ring buffer. Here's the complete code with detailed comments:
/* producer.c */
#define _POSIX_C_SOURCE 199309L // Enable POSIX features for clock_gettime
#include <time.h>
#include <stdio.h>
#include <stdlib.h>
#include <stdatomic.h> // For atomic operations
#include <unistd.h> // For ftruncate and sleep
#include <fcntl.h> // For shm_open
#include <sys/mman.h> // For mmap
#include <string.h> // For memset and snprintf
#define BUFFER_SIZE 1024 // Size of the ring buffer
#define SHM_NAME "/ring_buffer_shm" // Shared memory object name
#define NUM_MESSAGES 10000000 // Total number of messages to produce
// Define the RingBuffer structure
typedef struct {
atomic_ulong write_index; // Atomic write index
atomic_ulong read_index; // Atomic read index
char buffer[BUFFER_SIZE][64]; // Buffer to hold messages, each up to 64 chars
} RingBuffer;
/**
* Initializes the ring buffer in shared memory.
* Returns a pointer to the mapped RingBuffer.
*/
RingBuffer* init_ring_buffer() {
// Create or open the shared memory object
int fd = shm_open(SHM_NAME, O_CREAT | O_RDWR, 0666);
if (fd == -1) {
perror("shm_open");
exit(EXIT_FAILURE);
}
// Set the size of the shared memory object
if (ftruncate(fd, sizeof(RingBuffer)) == -1) {
perror("ftruncate");
exit(EXIT_FAILURE);
}
// Map the shared memory object into the process's address space
RingBuffer* ring_buffer = mmap(NULL, sizeof(RingBuffer),
PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (ring_buffer == MAP_FAILED) {
perror("mmap");
exit(EXIT_FAILURE);
}
close(fd); // Close the file descriptor as it's no longer needed
// Initialize the atomic indices
atomic_store(&ring_buffer->write_index, 0);
atomic_store(&ring_buffer->read_index, 0);
// Clear the buffer
memset(ring_buffer->buffer, 0, sizeof(ring_buffer->buffer));
return ring_buffer;
}
/**
* Produces a message and places it into the ring buffer using spinlock synchronization.
*/
void produce_spinlock(RingBuffer* ring_buffer, const char* message) {
// Atomically fetch and increment the write index
unsigned long write_index = atomic_fetch_add(&ring_buffer->write_index, 1) % BUFFER_SIZE;
// Write the message into the buffer at the calculated index
snprintf(ring_buffer->buffer[write_index], 64, "%s", message);
}
int main() {
// Initialize the ring buffer
RingBuffer* ring_buffer = init_ring_buffer();
printf("Producer: Waiting 10 seconds before starting production...\n");
sleep(10); // Delay to ensure the consumer is ready
struct timespec ts; // For timestamping messages
char message[64]; // Buffer to hold the message
// Produce messages in a loop
for (int i = 0; i < NUM_MESSAGES; ++i) {
// Get the current time for timestamping
clock_gettime(CLOCK_REALTIME, &ts);
// Prepare the message with an index and timestamp
snprintf(message, 64, "Message %d: %ld.%ld", i, ts.tv_sec, ts.tv_nsec);
// Produce the message using spinlock synchronization
produce_spinlock(ring_buffer, message);
}
printf("Producer: Produced %d messages.\n", NUM_MESSAGES);
return 0;
}
Key Points
- Shared Memory Initialization: The producer creates a shared memory object and maps it into its address space.
- Atomic Indices: The `write_index` is updated atomically to prevent race conditions.
- Spinlock Mechanism: The producer doesn't need to wait; it writes as fast as possible.
- Message Formatting: Each message includes an index and a timestamp.
Python Consumer Code
The consumer reads messages from the ring buffer and processes them. Here's the Python code with detailed comments:
# consumer.py
import os
import mmap
from ctypes import Structure, c_ulong, c_char, sizeof
import time
BUFFER_SIZE = 1024 # Must match the producer's buffer size
NUM_MESSAGES = 10000000 # Total number of messages to consume
SHM_NAME = '/dev/shm/ring_buffer_shm' # Path to the shared memory object
# Define the RingBuffer structure to match the C struct
class RingBuffer(Structure):
_fields_ = [
('write_index', c_ulong), # Atomic write index
('read_index', c_ulong), # Atomic read index
('buffer', (c_char * 64) * BUFFER_SIZE) # Buffer holding messages
]
def consumer_wait_spinlock(rb):
"""Waits until there is data to read in the ring buffer."""
while rb.read_index >= rb.write_index:
pass # Spin-wait; could add sleep to reduce CPU usage
def main():
# Open the shared memory object
fd = os.open(SHM_NAME, os.O_RDWR)
# Map the shared memory into the process's address space
size = sizeof(RingBuffer)
mm = mmap.mmap(fd, size, mmap.MAP_SHARED, mmap.PROT_READ | mmap.PROT_WRITE)
# Create a RingBuffer instance from the mapped memory
rb = RingBuffer.from_buffer(mm)
first_message_received = False # Flag to start timing
start_time = None # Variable to store the start time
# Consume messages in a loop
for _ in range(NUM_MESSAGES):
# Wait until there's at least one message to consume
consumer_wait_spinlock(rb)
# Start timing when the first message is received
if not first_message_received:
start_time = time.time()
first_message_received = True
# Calculate the current read index
idx = rb.read_index % BUFFER_SIZE
# Read the message from the buffer
message = rb.buffer[idx].value.decode('utf-8')
# Optionally process the message
# print(f"Consumed: {message}")
# Atomically increment the read index
rb.read_index += 1
# Calculate and print the total time taken to consume messages
end_time = time.time()
time_taken = end_time - start_time
print(f"Consumer: Consumed {NUM_MESSAGES} messages in {time_taken:.6f} seconds.")
if __name__ == "__main__":
main()
Key Points
- Shared Memory Mapping: The consumer opens the same shared memory object and maps it into its address space.
- Structure Matching: The `RingBuffer` class in Python matches the C struct layout to ensure correct memory interpretation.
- Spinlock Waiting: The consumer uses a spinlock to wait for new messages by comparing the `read_index` and `write_index`.
- Atomic Operations: The `read_index` is incremented to reflect that a message has been consumed.
Running the Code
To run the producer and consumer, follow these steps:
Compile the Producer
gcc -o producer producer.c -pthread
Run the Producer
./producer
Run the Consumer
python3 consumer.py
Performance Considerations
Using spinlocks can lead to high CPU usage because the consumer is constantly polling the indices. To mitigate this, you can introduce a small sleep in the spinlock loop:
def consumer_wait_spinlock(rb):
while rb.read_index >= rb.write_index:
time.sleep(0.0001) # Sleep for 0.1 milliseconds
However, this may introduce latency. The choice between CPU usage and latency depends on your application's requirements.
Extending the Pattern
While the spinlock approach is straightforward, for more advanced use cases, you might consider using futexes or other synchronization primitives to reduce CPU usage and improve performance. Additionally, you can adapt this pattern to support multiple consumers or producers with additional synchronization mechanisms.
Conclusion
Implementing high-performance inter-process communication between C and Python can be achieved using shared memory and atomic operations, inspired by the LMAX Disruptor pattern. This approach allows for minimal latency and high throughput, making it suitable for performance-critical applications like financial trading systems.
By carefully managing synchronization and understanding the trade-offs involved, you can build efficient IPC mechanisms that leverage the strengths of both C and Python in your application architecture.